Infrastructure ကိုင်ပြီး အိပ်ရေးမပျက် ချင် လျှင် ဒါမျိုး Alarms လုပ် 🔥🔥🔥

High Level ရေးထားတာပါ ဒါပေမဲ့ လွယ်ပါတယ်
ကိုယ့်မှာ AWS Infra တွေရှိတယ်ဆို တွေ့သမျှ metric တွေကို alarms တွေလုပ်ပြီး notification ယူမနေဘဲ တကယ် effective ဖြစ်တဲ့ metric တွေကိုမှ CloudWatch ရဲ့ alarm feature တွေနဲ့ ပေါင်းပြီး ပို့စေချင်ပါတယ်။
ဥပမာ product တွေ ကြေညာတဲ့ website အတွက် instance တလုံးရှိတယ်ဆိုပါစို့
100 မှာ 70 ရာခိုင်နှုန်းက လွယ်လွယ်ကူကူ CMS တမျိုးမျိုး အများဆုံးက WordPress နဲ့ လုပ်ကြတာများတယ်။ ဒီတော့ site ကို ဝင်ကြည့်တဲ့သူ များလာရင် Request Count တက်မယ်၊ လွယ်လွယ်ကူကူ ပြောရရင် CPU, Memory တက်လာမယ်ပေါ့။
သတ်မှတ်ထားတဲ့ Threshold ထက် ကျော်တာနဲ့ user ကြောင့် spike တာ ဖြစ်ရင်ဖြစ်၊ မဖြစ်ရင် အိန္ဒိယက အနဲ တို့ ကလိနေပြီ.... စတာ...

ဒီတော့ ဒီအခြေအနေတွေသိဖို့ alarms တွေ လုပ်ရပါတော့မယ်။
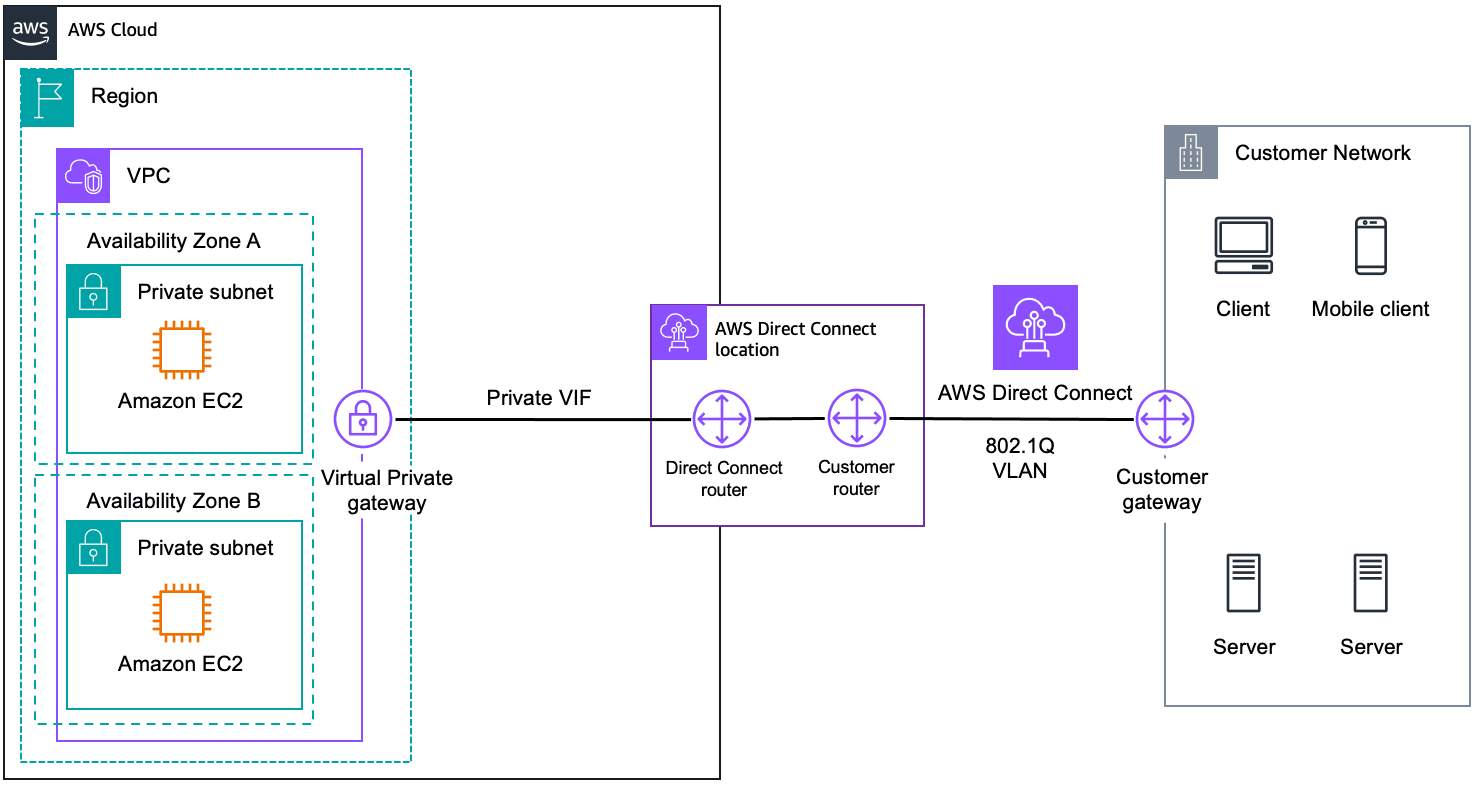
Instance ကနေ CloudWatch metric ကို 5 min တစ်ကြိမ် update တွေ ပေးပါတယ်။ ဒါပေမဲ့ CPU Utilization တစ်မျိုးပဲ များများ အထောက်အကူပြုနိုင်ပါတယ်၊ ကျန်တာက တစ်ခုခုကြောင့် debug လုပ်မှသာ ဝင်ကြည့်တာများပါတယ်။ Memory နဲ့ Disk ရဲ့ metric လိုချင်ရင်လည်း Unified Agent ကနေ သွင်းယူရမှာပါ။
ဒီတော့ ဘယ် metric တွေနဲ့ အလုပ်လုပ်သင့်လဲဆိုတာ မပြောခင် alarm ရဲ့ state ကို ခွဲထားဖို့ ပြောချင်ပါတယ်။ ဒီလိုခွဲဖို့အတွက် ကျွန်တော်ကတော့ critical နဲ့ high ဆိုတဲ့ SNS topic 2ခု AWS မှာ ကြိုဆောက်ထားလိုက်ပါတယ်။CW မှာ alarms create ရင် ဘယ် metric ကို ဘယ် topic ဆီပို့မလဲ ရွေးပေးသွားမှာပါ။
နောက်တစ်ခုက ဒီ alarms တွေ ဖန်တီးပြီးရင်တော့ ဘယ်ကို notification ပို့မလဲ ဆိုတာပါပဲ။
များသောအားဖြင့် email ကို ပို့ကြပါတယ်။ ကျွန်တော့်အမြင်ကတော့ ကိုယ့်ကိုယ်ကိုယ် ပြန်စိတ်ဒုက္ခမပေးသင့်ပါဘူး။
Email ကလည်း Office ကိစ္စ အရေးကြီးတဲ့နေရာ၊ မတူညီတဲ့ အဖွဲ့တွေကြားမှာ record ယူဖို့ သုံးကြတာပါ။ Infra Noti တွေကို လက်ခံဖို့ အတွက်သုံးခဲ့ရင် သေချာ manage လုပ်မထားရင် alarm email တွေနဲ့ရောပြီး တချို့ email တွေ ပျောက်သွားနိုင်ပါတယ်။
Team က Channel ကိုလည်း ပို့လို့ရပါတယ်။ ဒါပေမဲ့ Team အသံကလည်း လုံးဝကို ကင်ဆာပေးပါတယ်။ Team Channel တစ်ခုမှာ Alarm Noti တွေပါ ထပ်ထည့်ထားလို့ အသံကြားတိုင်း ကြည့်နေရရင် ဟုန်သွားပြီး တချို့အရေးကြီးတဲ့ message တွေ၊ conversation တွေ နောက်ကျသွားနိုင်ပါတယ်။
ဒီအချိန်မှာ Slack ဖြစ်ဖြစ် Discord ဖြစ်ဖြစ် သုံးသင့်တယ်လို့ မြင်ပါတယ်။ ကျွန်တော်ကတော့ Slack ကို ရွေးပါတယ်။ Setup လုပ်ရတာ လွယ်ပါတယ်။ Channel ဆောက်၊ Slack API ကနေ webhook ထုတ်ပြီး ဒီ webhook ထည့်ဖို့ Lambda function မှာ code လေး နည်းနည်းရေးပြီး trigger မှာ SNS ရွေးလိုက်ရင် Slack ကနေ message တွေကို ဖတ်နိုင်ပါပြီ။ AWS ရဲ့ message body ကို ဖတ်ရလွယ်အောင် Lambda မှာပဲ transform ဖို့ ရေးလို့ရပါတယ်။
CW metric နဲ့ alarm ဆီ ပြန်သွားပါမယ်။
Critical Channel ထဲ ဘာပို့မလဲ။ ကျွန်တော်ကတော့ instance အတွက်ဆို တစ်ခုပဲ ပို့ပါမယ် metric name က StatusCheckFailed ပါ။
StatusCheckFailed က instance ရဲ့ health ကို စစ်ပေးတဲ့ metric ပါ။ System Check (AWS hardware ပိုင်း) နှင့် Instance Check (OS သို့မဟုတ် Software ပိုင်း) ကိုစစ်ပေးပြီး တခု့ခု့ fail တာနဲ့ server down သွားနိုင်ပါတယ်။ CW မှာ status check fail ရင် alarm ထိပြီး instance reboot ပါ တစ်ခါတည်း ချလို့ရပါတယ်။
နောက် ဘယ် metric တွေကို high ထဲ ပို့မလဲ။
CPU Utilization, Memory used percent နဲ့ Disk usage တို့ကို High ထဲ ပို့ပါမယ်။ Application Load Balancer သုံးထားတယ်ဆိုရင် Request metric နဲ့ 5xx error ကိုပါ ပို့ပါမယ်။
ဒီမှာ အဓိကပြောချင်တာက CW မှာ alarms ဘယ်လို create လုပ်မလဲဆိုတာပါ။ ပုံမှန်ဆို metric ရွေးမယ်၊ max နဲ့ တိုင်းမလား AVG နဲ့ တိုင်းမလား ရွေးမယ်။ Interval ကတော့ 5 min ပဲ ထားကြတာများတယ်၊ 1 min ထားရင်လည်း instance ဘက်က detailed monitoring ဖွင့်ပေးမှ metric တွေ 1 min တစ်ခါ ပို့နိုင်မှာဖြစ်ပြီး ဈေးကလည်း ပုံမှန်ထက်ပိုကြီးပါတယ်။ ပြီးရင် Threshold မှာ 80 လောက် ထားမယ်။ high ထဲ ပို့ပေမဲ့ 80 လောက်တော့ ထားသင့်တယ်လို့ မြင်တယ်။ ပြီးရင် SNS topic ရွေး၊ ပြီးပြီ။
အဲ့မှာ သတိမထားမိရင် ကျော်သွားမှာရှိတယ်၊ ဘာလဲဆိုတော့ datapoint ပါ။ ဒီဟာလေးက တအား အသုံးဝင်ပါတယ်။ Default က 1 out of 1 ပါ။ ဘယ်လိုအလုပ်လုပ်လဲဆိုရင် ဥပမာအနေနဲ့ CPU Utilization ရဲ့ AVG 5 min interval အတွင်းမှာ သတ်မှတ်ထားတဲ့ Threshold ထက် တစ်ကြိမ်ကျော်ခဲ့ရင် alarm ထိပြီး Noti ပို့ပါမယ်။ ဒီ 5 min အတွင်း 1 ကြိမ်၊ အလွယ်ပြောရရင် 1 min သာ CPU တက်ပြီး ပြန်ကျသွားလည်း Noti ပို့မှာပါ။ ပြောရရင် မလိုအပ်ပါဘူး၊ False positive alarm လို့တောင် ပြောလို့ရပါတယ်။
ဒီလိုမျိုး မဖြစ်စေချင်ဘူးဆိုရင် 3 out of 3 ထားလို့ရပါတယ်။ 5min တိုင်းမှာ 1 ကြိမ်စစ်တာ 3 ကြိမ်လုံး ( စု့စု့ပေါင်း 15 min ) Threshold ထက် ကျော်နေမှ ပို့မှာပါ။ Noise တော်တော် လျော့သွားမှာပါ။ ဒီ data point ကစားတာက CPU Utilization နဲ့ Memory used percent အတွက်ပါ။ ကျန်တဲ့ဟာတွေ မလိုပါဘူး default ထားလို့ရပါတယ်။
အကယ်၍ AWS Auto Scaling Group သုံးခဲ့ရင် CPU ရော Memory ရော alarm မယူတော့သင့်ပါဘူး။ ASG မှာ Unified Agent ထည့်ထားတာကလည်း CW မှာ metric တွေကို များလာစေပြီး မျက်စိနောက်ပါတယ်။
များသောအားဖြင့် API server တွေ ဖြစ်နိုင်တဲ့အတွက် Open source tools တမျိုးမျိုးနဲ့ဖြစ်စေ New relic ဖြစ်စေ ထည့်တာက ပိုအဆင်ပြေပါလိမ့်မယ်။ ASG မှာလည်း Scaling policy တစ်မျိုးမျိုး ရှိနေမှာဖြစ်တဲ့အတွက် သတ်မှတ်ထားတဲ့ Threshold ဆိုရင် scale မှာပါ။ Metric တစ်မျိုးကိုပဲ ထပ်တိုးပြီး Critical Channel ထဲ ထည့်ထားသင့်ပါတယ်။ အဲ့ဒါကတော့ UnhealthyHostCount ပါ။ Application Load Balancer နဲ့ တွဲထားတဲ့ Target Group ကနေ ယူရမှာပါ။ ဒီ metric ကြောင့် ASG ထဲက instance လစ်သွားရင် သိပါလိမ့်မယ်။
RDS ကတော့ နည်းနည်း ပိုလုပ်ရပါမယ်။ Critical ထဲထည့်မှာပါ DB ဖြစ်တဲ့အတွက်။Critical Channel ထဲ ထည့်ဖို့အတွက် သေချာလေး စဉ်းစားပြီး ရေးပါမယ်။ ပုံမှန် CPU Utilization ရှိပါမယ်၊ သူက ၁ မိနစ် တစ်ခါ metric update ပါတယ်။ ဒီတော့ interval ကို 1 min ထားပြီး datapoint ကိုတော့ အနည်းဆုံး 10 out of 10 ထားသင့်ပါတယ်။ ဒါတောင် user spike ရှိရင် ခဏခဏ တံခါးလာခေါက်နေမှာပါ။ ဒီတော့ Read Latency နဲ့ Write Latency လေးပါ alarm လုပ်၊ ဒါကို CW ရဲ့ Composite Alarm နဲ့ ဒီ metric တွေကို ပြန်အုပ်ကာ Noti ယူသင့်ပါတယ်။ Aurora Serverless ဆိုရင် ACU Utilization လေးကိုပါ 10 out of 10 datapoint အနည်းဆုံးလေးနဲ့ ထားသင့်ပါတယ်။
ဒါကတော့ Alarm Noti တွေရဲ့ နှိပ်စက်မှုကနေ ဝေးအောင် လက်ရှိ သုံးကြည့်နေတာလေးပါ။